Hello, I am Rithesh Kumar, a Senior Research Scientist on the Speech AI team at Adobe Research.
I lead speech generation research focused on controllable text-to-speech synthesis, automatic dubbing, and speech
editing. My work centers on
scaling diffusion models and developing efficient distillation algorithms for multilingual audio generation.
Previously, I was Technical Lead for Audio Research at
Descript Inc., where I built and shipped 4+ text-to-speech models powering the
flagship Overdub and Regenerate features—enabling ultra-realistic voice cloning and
text-based audio corrections.
As a firm believer in the bitter lesson, my research goal is to develop scalable multi-modal models that bridge the reasoning and general intelligence of LLMs with diffusion models that can synthesize natural signals like audio, video, and images at the highest quality.
Currrently, I live in Toronto, Ontario 🇨🇦.
Research to Product


Education
I completed my MSc in Computer Science (specializing in Artificial Intelligence) at the Mila lab in Université de Montréal supervised by Yoshua Bengio. During my MSc, I had the excellent opportunity to intern at Lyrebird and Microsoft Research - Montréal.
Earlier, I graduated from SSN College of Engineering (affiliated to Anna University) with a Bachelors in Computer Science and Engineering. I spent the final 2 years of my undergrad learning about deep learning, spending a summer at the Serre Lab in Brown University and collaborating with Prof. Yoshua Bengio at the Mila lab.
Select Publications

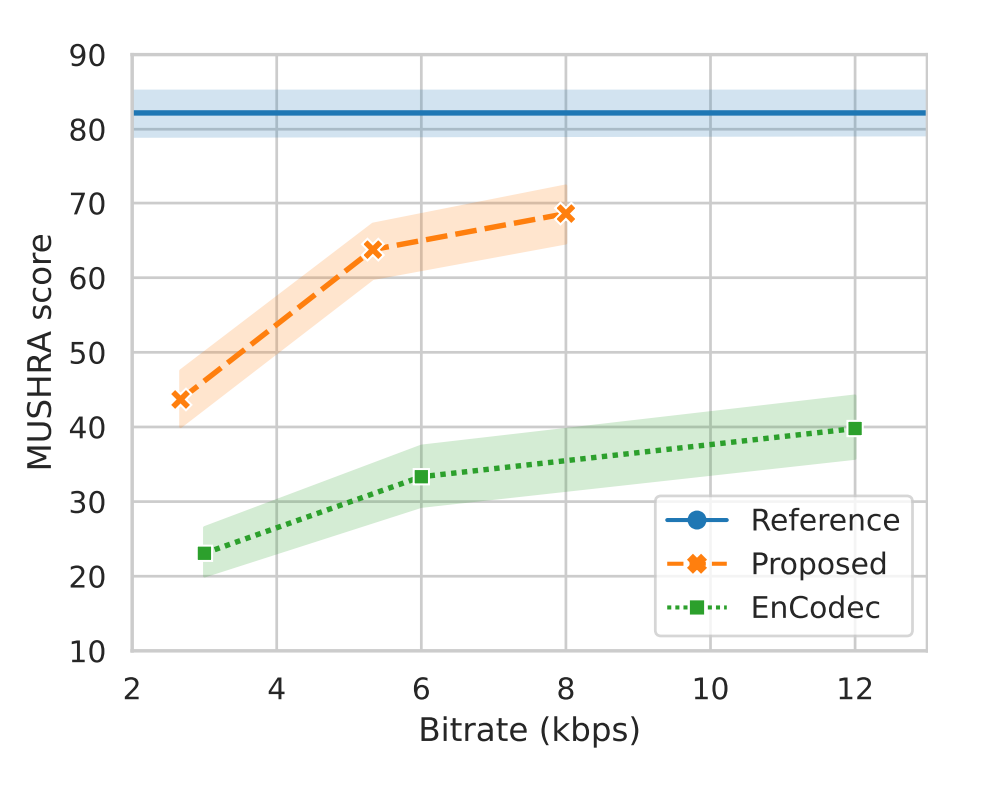
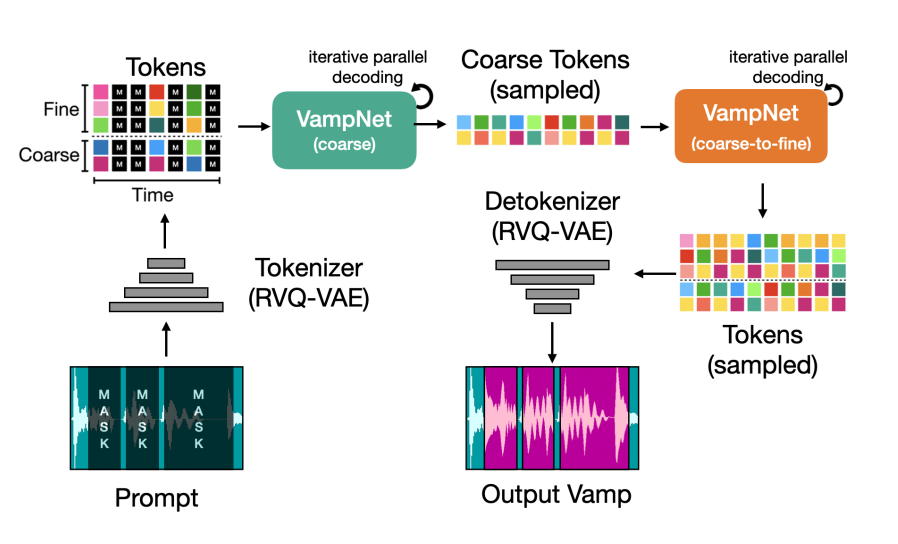
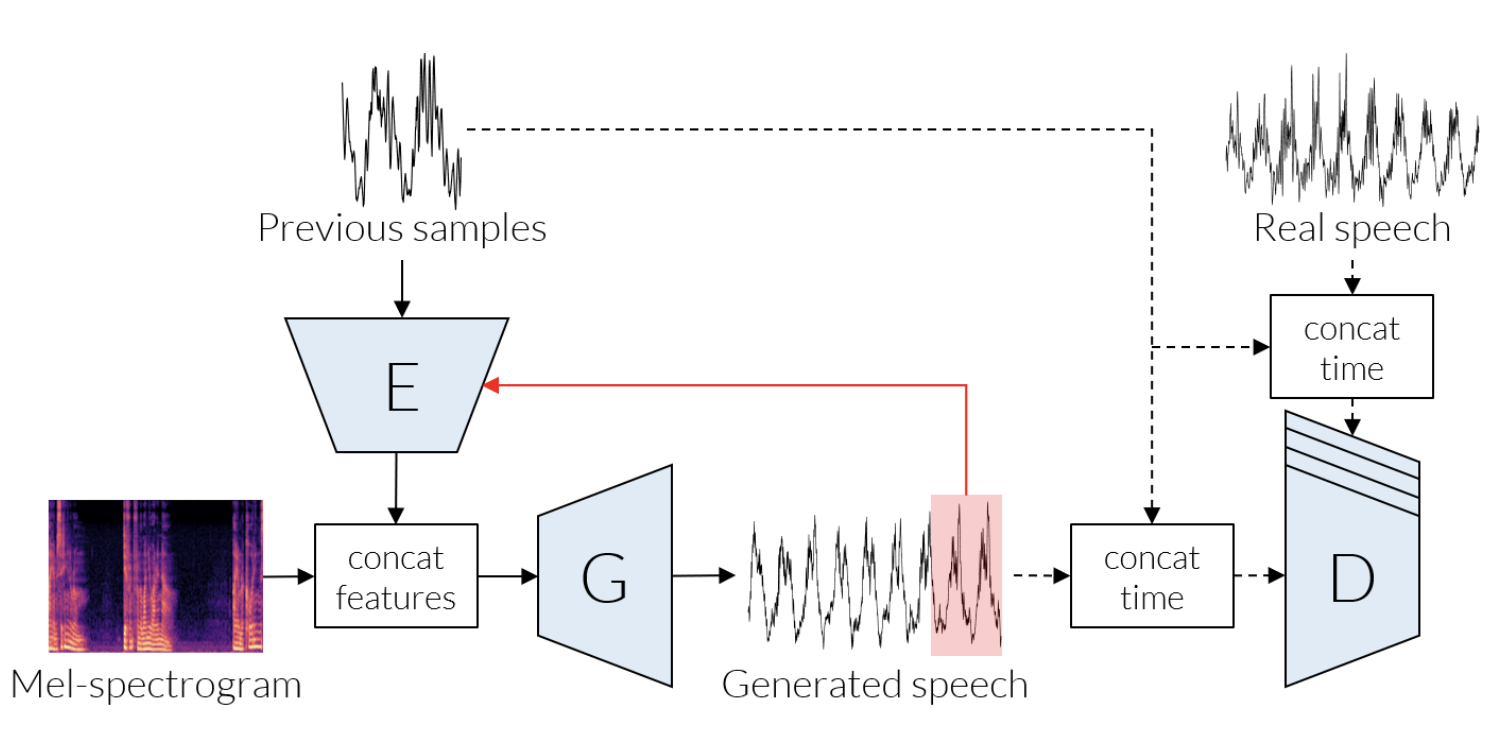


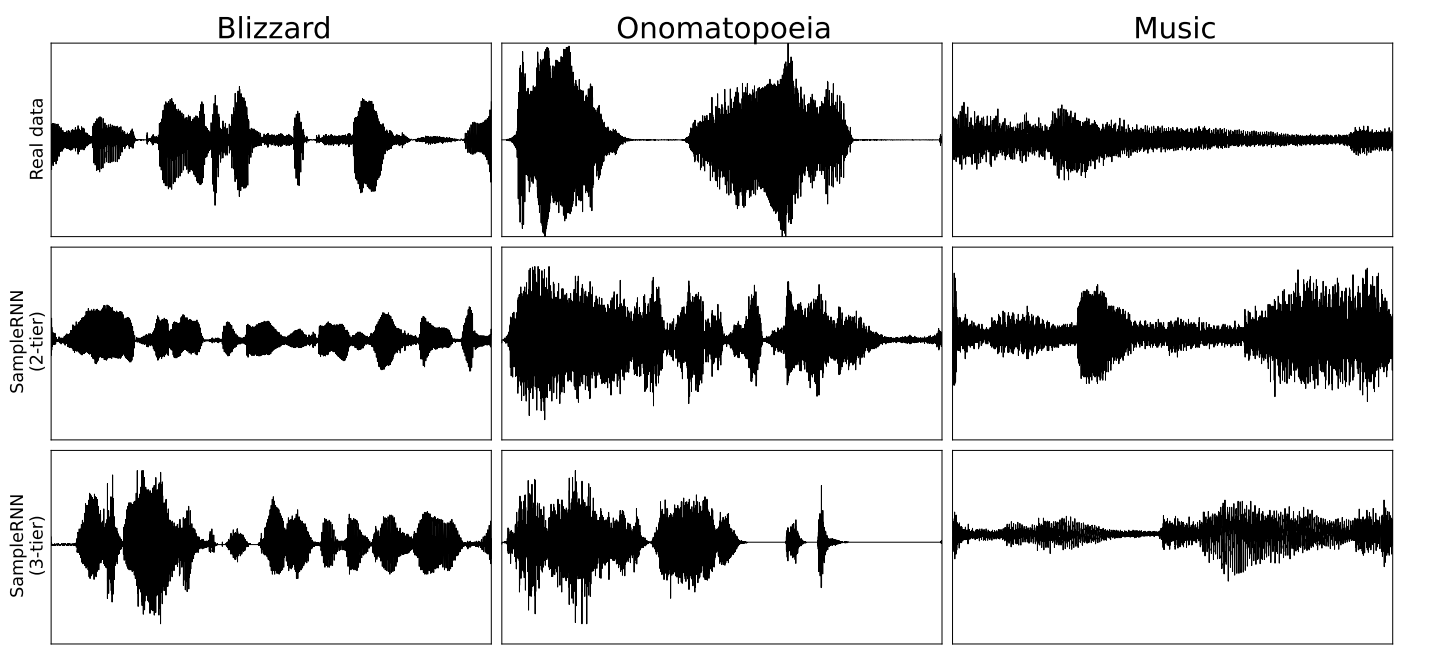
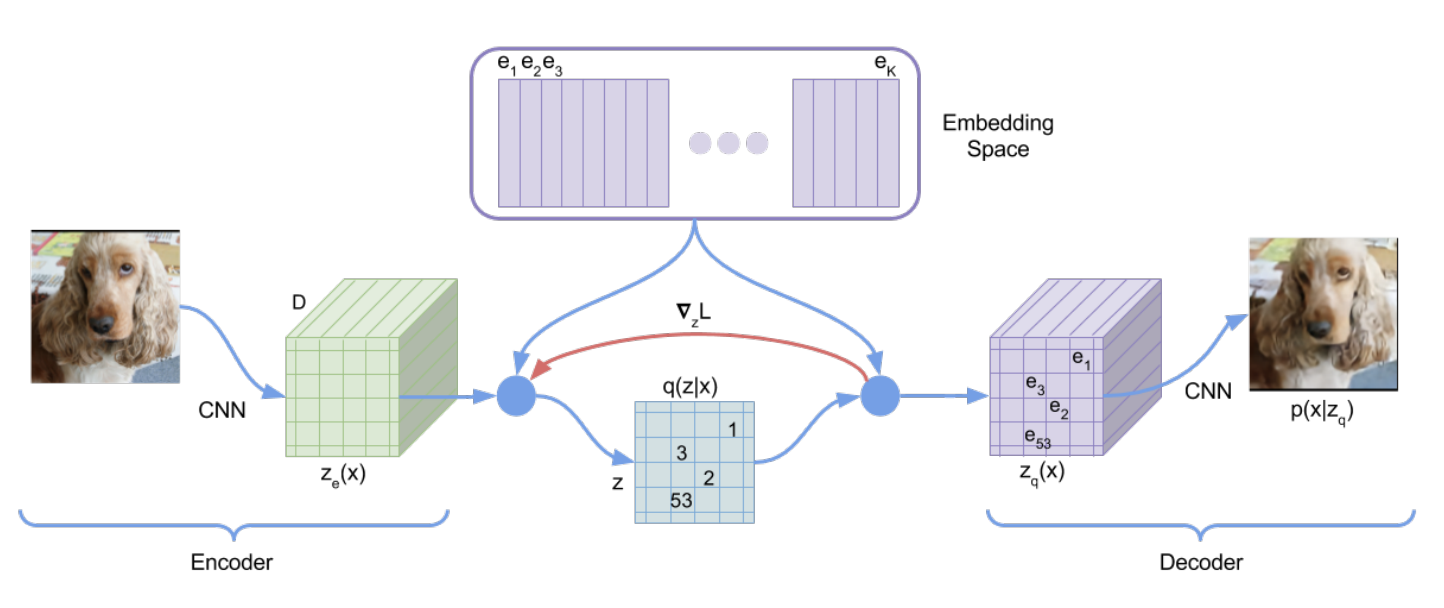
Select Projects